Most mathy people have a pretty good mental model of what a random process is (for example, generating a sequence of 20 independent bits).
I think most mathy people also have the intuition that there’s a sense in which an individual string like 10101001110000100101 is more “random” than 0000000000000000000 even though both strings are equally likely under the above random process, but they don’t know how formalize it, and may even doubt that there is any way to make sense of this intuition.
Mathematical logic (or maybe theoretical computer science) has a method for quantifying the randomness of individual strings: given a string 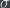
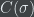
In this blog post, I would like to explain why I think this is a very satisfying definition.
Keeping Grounded
I think a good way to help avoid philosophical quagmires when thinking about randomness is to recognize that random numbers are useful in the real world, and to make sure that your thinking about randomness preserves that.
For example, there are algorithms 
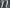
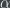
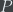
Just to give a concrete example: a very familiar way that random numbers are useful is to estimate the average of a large list of numbers by taking a random sample and averaging them. You might have a list of 1000 numbers (say, bounded between 0 and 10), and have
The reason that I think that the Kolmogorov complexity is a good account of randomness is that they above story “factors” through Kolmogorov complexity in the following way: For any computable 
- For all
with
,
returns a correct answer.
- Almost all
(of the given length
) have
.
 ,
, That is, Kolmogorov complexity lets you view the problem as follows: Any string of high complexity will yield the right answer when fed into
As a note: the notation 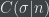
Some Rough Intuitions
The intuition for why almost all strings 

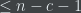

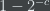
The intuition for why 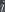

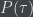
Formalization
I said above that this fact about Kolmogorov complexity only holds if
enough. How can we formalize this? One approach would be to consider a sequence of algorithms 

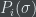
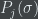
Now, if we kept the size 


In fact, it turns out we can just describe in terms of the sets of input strings on which the algorithm returns a correct answer.
Definition: A P-test
is an assignment of a natural number to each
finite stringsuch that, for each
, the number of
of length
such that
is
.
 is an assignment of a natural number to each
is an assignment of a natural number to each is
is  .
.If 



Theorem (Martin-Löf?): For any computable P-test
, there is a constant
such that: For all
of length
and natural numbers
, if
, then
.
Furthermore, the proportion of
such that
is at least
.
 , then
, then  .
. .
.I think this was one of Martin-Löf’s original theorems but I’m actually not sure. It’s a rephrasing of the results in Section 2.4 of Li and Vitányi’s book.
So, there is a complexity bound such that any string of high enough complexity will return a correct answer when plugged into the algorithm. However,
may have to be made high (which corresponds to making
that there are a large number of such high complexity strings (or any at all).
What about Noisy Data?
The algorithms discussed above are all deterministic: that is, they correspond to things like Monte Carlo integration rather than averaging noisy data collected from the real world.
So what about noisy data? Random numbers are also useful in analyzing real world data, but the theorem above only applies to computable algorithms. The answer is so simple that it seems like cheating: if you model the noise in your data as coming from some infinite binary sequence 

What about Infinite Random Sequences?
Above we considered algorithms that knew ahead of time how many random bits we need. What about algorithms that might request a random bit at any time? This is also handled by Kolmogorov complexity: here we say that an infinite binary sequence is Martin-Löf random if there is some 
As in the finite case, there’s a theorem saying that any sufficiently robust algorithm will yield a correct answer on any Martin-Löf random sequence.
One thing I like about this framework is that it provides an idea for what it means for a single infinite sequence to be random. For example, people often say that the primes are random (in fact, it’s one of their main points of interest). Since the primes are computable, they aren’t random in this sense, but this gives an idea of what it might mean: perhaps there’s some programming language that encapsulates “non-number-theoretic” ideas in some way, and some sequence derived from the primes can be shown to be “Martin-Löf” random with Turing machines replaced by this weaker description language. But this is pure speculation.