Mathematical logic has a categorization of sentences in terms of increasing complexity called the Arithmetic Hierarchy. This hierarchy defines sets of sentences 

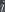
and
are both equal to the set of sentences
such that a computer can determine the truth or falsity of
in finite time.Sentences in
are essentially computations, things like
or “For all
less than a million, if
then
.”
for
is defined as follows: If, for all
,
is a
sentence, then
is a
sentence.
- Similarly, if for all
,
is a
sentence, then
is a
sentence.
 and
and  are both equal to the set of sentences
are both equal to the set of sentences  are essentially computations, things like
are essentially computations, things like  or “For all
or “For all  less than a million, if
less than a million, if  then
then  .”
.” is defined as follows: If, for all
is defined as follows: If, for all  is a
is a  sentence, then
sentence, then  is a
is a  sentence, then
sentence, then  is a
is a It’s not obvious from the definition, but by encoding pairs, triples, etc. of natural numbers as single natural numbers, you are allowed to include multiple instances of the same quantifier without moving up the hierarchy. For example, a sentence 





Many number-theoretic and combinatorial statements are
Note that statements of the form 

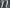

There are many sentences which are of the form 




There is a theorem that the sentences in this hierarchy actually do get harder to decide the truth of in general:
Theorem: For any
: even in a programming language augmented with the magical ability to decide the truth of
sentences, it is not possible to write a program which decides the truth of every
sentence.
 sentence.
sentence.A Scientific Hierarchy
What if we used the above idea to classify scientific statements instead of number-theoretic ones? We would get a new hierarchy where:
and
are both equal to the set of sentences
such that a definite experiment can be performed which demonstrates the truth or falsity of
.
and
for
are defined just as before.
Examples of
Of course, those examples are idealized: to make them actually true, you have to add in lots more caveats and tolerances: for example, you have to say that any pair of objects weighing no more than such-and-such will fall with the same acceleration up to such-and-such tolerance (and add in various other caveats). More on this later.
An example of a
You might have to use a statement of complexity 


A Scientific Hierarchy Theorem?
In the Arithmetic Hierarchy case, we had a theorem saying that statements higher up the hierarchy were qualitatively harder to decide the truth of. Is there a similar theorem here?
In fact, you can make this precise (although, to be honest, I’m not sure what the cleanest way to do it is). In particular, 



Now, suppose that you have a probability distribution over all possibilities for 




Call events which are finite conjunctions of events of the form 
Now say that this probability distribution is open-minded with respect to an event 


Now, assuming that 


On the other hand, for general 


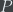
I would like to emphasize though, that the above are off-the-cuff basically-trivial observations. There must be a cleaner, nicer framework to state a scientific hierarchy theorem, but I don’t know what it is.
Science is Hard
In my opinion, thinking about the complexity of scientific statements in terms of quantifiers yields some insights.
For example, the
The fact that science is not so simple is seen by just recognizing that there are scientific hypotheses that are not in
- Measurement errors.As alluded to above, to make our scientific statements true, we have to add tolerances. If we don’t know what the tolerances should be when we make the hypothesis, we have to add at least one quantifier.
- Not everyone can perform the experimentsNot everyone performs experiments, in fact, most people rely on scientific consensus.
That automatically brings the hypothesis up to (at least), for example:
There exists a time, such that for all times
the scientific consensus at time
will be in favor of global warming (or evolution, or that eggs are good for you, or whatever).
 , such that for all times
, such that for all times  the scientific consensus at time
the scientific consensus at time  will be in favor of global warming (or evolution, or that eggs are good for you, or whatever).
will be in favor of global warming (or evolution, or that eggs are good for you, or whatever).Where can I go for more information?
I feel like thinking about the complexity of scientific hypotheses in terms of quantifier alternations is so natural that it must have been studied before, but I can’t find anything by googling around. Does anyone know where to find more information on this?



















